
时间: 2024-07-20 00:36:12 | 作者: 产品展示
日前火山翻译团队发布《请翻译2020》年度盘点,详解过去一年上线的火山翻译Studio、火山同传等新品,以及在训练机器翻译模型过程中遭遇的技术难点和解决方案。2020年最后三天,火山翻译的调用量达日均。如果把火山翻译每天翻译的字符打印在A4纸上,堆起来的纸张相当于1.3个东方明珠的高度。
在2020年国际机器翻译大赛(WMT20)上斩获冠军后,火山翻译团队正投入在mRASP 、LightSeq和MGNMT等创新技术上。新技术的实践将创造更激动人心的体验,或许在2021年,火山翻译会带来更多惊喜。
在火山翻译团队多年的技术积累、产品设计和方案支持下,火山翻译提供了火山同传、火山翻译API、火山翻译Studio、浏览器翻译插件等一系列矩阵产品。
2020年3月,火山翻译团队开发的新型AI视频翻译工具——火山翻译Studio V0.1版本上线,并面向用户进入内测阶段。
借助先进的自动语音识别和神经机器翻译技术,火山翻译Studio为视频创作者们提供专业高效的视频「转写-打轴-翻译」全流程服务,将视频译制流程中,三件复杂的工作「一站式」完成。产品支持交互式翻译和术语干预等多种辅助翻译功能,在提高翻译效率的同时,让字幕翻译更加个性化。这款工具营造了更良好的双语字幕制作环境,大幅度的降低了双语字幕的制作成本,帮助用户轻松解决视频内容的跨语言传播问题。
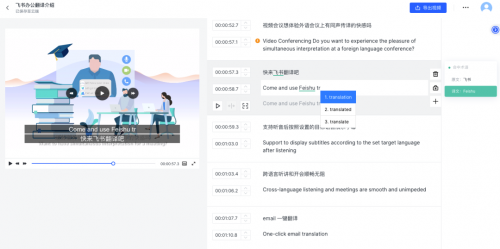
火山翻译Studio,自动生成双语字幕,支持交互式翻译和术语干预等多种功能
2020年10月,火山翻译团队发布了智能同传产品——火山同传,致力于为线下会议、线上直播提供实时机器同传服务。一年来,火山同传先后服务和参与了飞书未来无限大会、知名艺术家村上隆首场中国直播、第四届CTDC首席技术官领袖峰会等多场直播与大会。
为确保实时翻译的准确性和实时字幕的最佳展示效果,火山同传提供「全屏逐字式字幕显示方案」和「影院级字幕重保方案」,满足多种场景的需求。产品包含55种语言翻译及中英日三语听写识别等高性能服务能力,借助人工保障方案,实时校准,保证字幕精准性和流畅性。独家提供的「VFT领域自适应服务」,让翻译算法的翻译风格更贴合会议在语体等方面的需求,为直播字幕展示效果提供了更优路径。

11月,火山翻译网页版正式上线,并发布了中英双语版本,集成了PC端和WAP端的在线翻译工具与其他相关这类的产品的介绍页面。
火山翻译在线个语种全语向互译,单次可翻译高达2000字符。网页提供「语种全自动检测」、「译文一键复制」、「双语对照查看」等功能,用户都能够高效获取跨语言翻译服务。
产品介绍页则系统展示了「机器翻译API」、「视频字幕翻译」、「智能同传」等火山翻译旗下的高品质的产品,此外还提供了「网页翻译-浏览器插件」等应用的体验入口。火山翻译面向B端客户的相关服务能力也已集成在火山引擎智能应用板块当中,为更多客户提供企业级的技术产品与解决方案。

强大的翻译应用背后离不开火山翻译团队的算法科学家、工程师团队历时数年的努力。在完整服务日均过亿次调用的基础上,团队追求支持更多语向、提供更好的翻译服务。
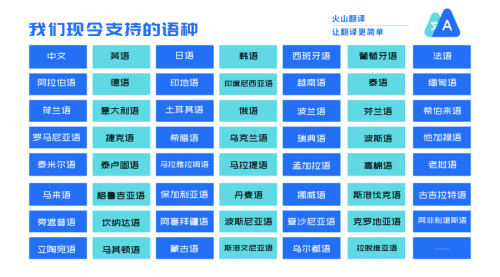
这一年,火山翻译在翻译语种扩展上持续发力,从最初的几门语言,到现今支持55个语种、2970个语向之间的互译。这中间还包括马其顿语、斯洛文尼亚语、乌尔都语、旁遮普语等小语种。
某些翻译领域的鲜见性加剧了模型训练的难度,尤其是「泛娱乐场景」这样具有高度不规范性和娱乐性的翻译领域。对此,火山翻译综合运用「NMT领域适应、领域数据增强、大模型学习、多领域模型」等更多领域的方法,结合各领域的特点来优化,攻克了领域冷门问题带来的算法优化障碍。
「语种数量多、小语种的平行语料匮乏」一直是训练机器翻译模型工作中的痛点。在平行数据稀缺的情景下,火山翻译的工程师们使用基于「自研Fluid平台」的半监督训练体系,开展多语言的预训练工作,成功构建出了「多语言」翻译模型,攻克了平行数据缺乏而造成的模型效果不佳、翻译性能不达标等技术难题。

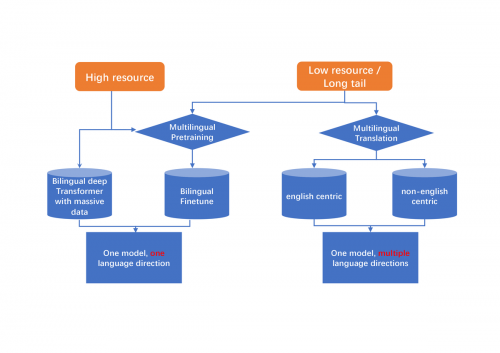
“业务的奔跑中资源永远是不够的”。在算法的训练和优化进程中,由于GPU资源的紧缺,待训练的语种数量却很庞大,火山翻译团队亟待提升GPU的利用率来应对棘手的挑战。对此,团队使用了「多语言翻译模型」来整合资源,同时进行多个长尾语种的训练,将资源利用率极大的提升,成功满足大量级服务的需求。
不断打破语种表现的天花板,持续迭代提升各语向翻译质量,火山翻译在国际舞台上表现出不俗的竞争力。
在2020年国际机器翻译大赛(WMT20)上,火山翻译团队在39支参赛队伍中杀出重围,以显著优势在「中文-英语」的关键语向翻译项目竞赛上拿下了世界冠军。此外,火山翻译还拿下了「德语-英语」、「德语-法语」、「英语-高棉语」和「英语-普什图语」语向机器翻译项目的冠军,更斩获了平行语料过滤对齐项目普什图语和高棉语的两项第一。
历年比赛中,「中文-英语」语向的翻译任务都是参赛队伍最多、竞争最为激烈的机器翻译任务之一。火山翻译作为一只年轻的团队,参加了「非受限场景」的比赛——即在给定测试集的情况下,允许用任何数据和方法探索翻译效果极限的比赛方式。同时,组织方也引入了四个权威的在线机器翻译商业系统(Online-A、G、Z、B)作为对比。这种比赛模式被认为是“最能体现翻译团队数据和算法综合能力”的场景。经过比赛组委会邀请的语言专家的系统评估,火山翻译以明显的优势夺得了该项冠军。

WMT20 中英翻译前几名系统得分,火山翻译排名第一。Ave.z代表人工评估标准化分数,也是目前机器翻译最受认可的指标。
相比「中文-英语」语向,「德语-英语」语向则是WMT比赛上的传统项目之一,也是最受欧洲国家的代表队们关注的竞赛语向。在「德语-英语」比赛最后的人工评价环节中,火山翻译依然表现出杰出的技术水准,拿下第一名的成绩。最终,国际机器翻译大赛的组委会对于团队给出了很高的评价,“作为新的参与者,火山翻译表现尤为出色(particularly well),超越了很多传统队伍”。
下图为火山翻译和谷歌翻译在各语向测试集上的表现对比信息,横轴为语向信息,纵轴展示了BLEU值的差值。从图中的数据可见,在左侧棕域表示的多数语向上,火山翻译模型的自动评估结果均高于谷歌。其中「日语-中文」、「印尼语-英语」、「中文-日语」三个语向更是比谷歌翻译高出了10个BLEU值以上。(注:BLEU全称Bilingual Evaluation Understudy,是最普遍的使用的机器翻译自动评价指标)
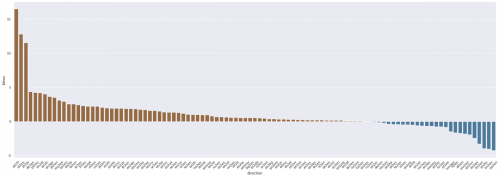
在和英语进行互译的语向中,火山翻译有72%的机器自动评价结果优于谷歌翻译。火山翻译也正持续追求在更多语向上获得优质表现,争取为全球更广泛的用户群体提供令人满意的翻译服务。
在2020年最后三天,火山翻译日均翻译的字符数达到百亿规模,翻译调用量达日均1.38亿次,稳定服务包括飞书、今日头条在内的数十个业务。火山翻译可通过公有云、私有化部署等多种形式接入,支持垂直行业模型快速定制和部署,满足各垂直行业的个性化翻译需求。
对翻译产品和服务来说,无论是模型还是推理能力,都需要持续的创新和投入。在2020年度盘点中,火山翻译团队披露了正在持续探索和实践的翻译技术:
多语言翻译新范式mRASP(multilingual Random Aligned Substitution Pre-training)建立的核心思想是打造「机器翻译界的BERT模型」,即通过预训练技术进行规模化训练,再在具体语种上进行精细微调,即可达到领先的翻译效果。其在32个语对上预训练出的统一模型,在至少47个翻译测试集上均取得了全面的明显提升。在火山翻译中,该技术已被广泛使用,得到了业务上的实践检验。
以BERT为代表的预训练范式几乎横扫了所有的文本理解任务,成为各种NLP任务的基石。mRASP不同于以往的机器翻译范式,树立了机器翻译的预训练和微调的成功路径。
不论平行双语资源高低,均能有提升。对于资源丰富的语言,比如标准英法翻译任务,在已经有4000万平行语句训练情况下,使用mRASP依然能显著提升,达到了44.3的BLEU值。在低资源语言上,mRASP的表现令人惊喜,极端情况下,只需要一万句训练数据,通过10分钟微调训练,就能得到一个还不错的翻译系统。
任何语言的翻译,无论是孟加拉语到古吉拉特语,还是印地语到菲利宾语,只要是地球上的语言,都可以用mRASP直接进行微调,并且效果可期。
相比于其它上百张卡的「军备竞赛」预训练玩法,mRASP更平民,仅需要8张卡训练一周就能够实现。简单来说,mRASP能够理解为机器翻译领域的轻量级BERT,只要是机器翻译任务,对于任何场景或者语言,使用mRASP都可能会有意想不到的收获。
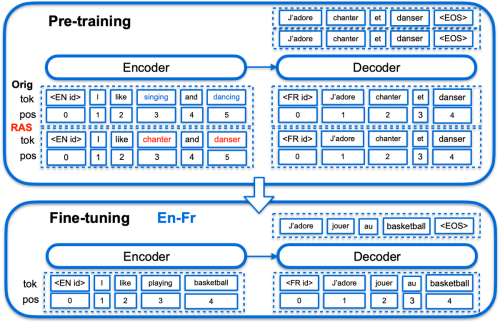
mRASP基于Transformer框架,利用多个语对的平行语料建立预训练模型
LightSeq是一款极速且同时支持多特性的高性能序列推理引擎,它对以Transformer为基础的序列特征提取器(Encoder)和自回归的序列解码器(Decoder)做了深度优化,早在2019年12月就已经开源,应用在了包括火山翻译在内的众多业务和场景。据了解,这应该是业界第一款完整支持Transformer、GPT等多种模型高速推理的开源引擎。
LightSeq能应用于机器翻译、自动问答、智能写作、对话回复生成等众多文本生成场景,大幅度的提升线上模型推理速度,改善用户的使用体验,降低企业的运营服务成本。
LightSeq推理速度很快。以翻译任务为例,LightSeq相比于TensorFlow实现最多能够达到14倍加速。同时领先目前其他开源序列推理引擎,例如最多可比Faster Transformer快1.4倍。
LightSeq通过定义模型协议,支持灵活导入各种深度学习框架训练完的模型。同时包含了开箱即用的端到端模型服务,即在不需要写一行代码的情况下部署高速模型推理,并灵活支持多层次复用。
镜像翻译生成模型MGNMT(Mirror-Generative Neural Machine Translation)旨在解决机器翻译在双语平行数据缺乏场景中的应用问题,目前已应用到火山翻译多个语向的翻译模型中。通过镜像生成方式,MGNMT利用互为镜像翻译方向的相关性,同时将翻译模型和语言模型结合,让模型间互相促进,从而明显提升翻译质量。
目前机器翻译模型需要在大量的双语平行数据上训练,从而得到不错的性能。然而,在很多低资源的语向或领域场景中,双语平行数据是非常稀缺的。这种情况下,双语平行数据非常珍贵,需要更高效地利用;并且由于双语数据稀缺,充分的利用大规模非平行单语数据也十分重要。
为了最大化对双语数据和单语数据的有效利用,MGNMT采用了以下几种关键技术:
1. 通过一个共享的隐变量,将两个翻译方向的翻译模型和两个语言的语言模型结合在同一个概率模型中。
2. 训练时,两个翻译方向相互促进。通过隐变量建模了互为译文的双语数据的语义等价性,让两个翻译方向的模型可以更好地利用双语平行数据;同时,通过隐变量作为中间桥梁,任意一方的单语数据都可以同时帮助到两个翻译方向的模型,从而也更好地利用了单语数据。
3. 解码时,语言模型和翻译模型相互协作。正向翻译模型和目标语言模型首先用beam search进行协同解码,得到多个候选译文;随后反向翻译模型和源语言语言模型对候选译文进行排序,选择出最忠实于原文语义的最佳译文。
在低资源的情况下,MGNMT在多个数据上都得到了最好的翻译结果。相较于传统的Transformer模型,以及Transformer结合回翻译(Back-Translation)进行数据增强以利用单语数据的方式,其结果都显示了比较一致的、显著的提升。
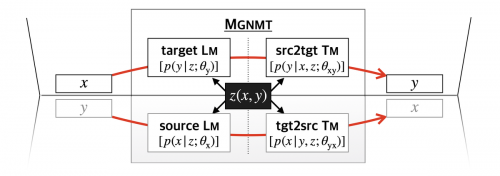
MGNMT模型示意图。MGNMT同时建模了两个翻译方向的翻译模型和两个语言模型。
“我们和你一样,一步一踉跄,却坚定不移。我们和你一样,经历波折,却满怀希望”。在《请翻译2020》年度盘点中,火山翻译团队表示,为了呈现更佳的翻译效果,创造更好的跨语言体验,火山翻译孜孜不倦地为不同的语言提供最优解法,为了“让世界更小,让不同的文化更近”。